redis布隆过滤器
redis布隆过滤器
1.布隆过滤器使用场景
比如有如下几个需求:
①、原本有10亿个号码,现在又来了10万个号码,要快速准确判断这10万个号码是否在10亿个号码库中?
解决办法一:将10亿个号码存入数据库中,进行数据库查询,准确性有了,但是速度会比较慢。
解决办法二:将10亿号码放入内存中,比如Redis缓存中,这里我们算一下占用内存大小:10亿*8字节=8GB,通过内存查询,准确性和速度都有了,但是大约8gb的内存空间,挺浪费内存空间的。
②、接触过爬虫的,应该有这么一个需求,需要爬虫的网站千千万万,对于一个新的网站url,我们如何判断这个url我们是否已经爬过了?
解决办法还是上面的两种,很显然,都不太好。
③、同理还有垃圾邮箱的过滤。
那么对于类似这种,大数据量集合,如何准确快速的判断某个数据是否在大数据量集合中,并且不占用内存,布隆过滤器应运而生了。
2.设计思想
布隆过滤器是一个由 一个长度为 M 比特的位数组(bit array)与 K 个哈希函数(hash function) 组成的数据结构。布隆过滤器主要用于用于检索一个元素是否在一个集合中。
位数组中的元素初始值都是 0 ,所有哈希函数可以把输入的数据均匀低散列。图例如下:
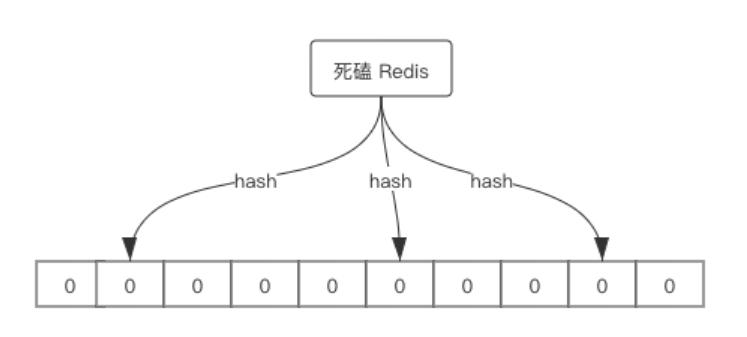
当要插入一个元素时,将其输入 K 个哈希函数,产生 K 个哈希值,同时以这些哈希值作为位数组的下标,将这些下标对应的比特值设置为 1。
当要查询一个元素时,同样是将其输入 K 个哈希函数,产生 K 个哈希值,然后检查这些哈希值中对应的比特值。如果有任意一个比特值为 0,则表明该元素一定不存在,如果所有比特值都是 1,则表明该元素可能存在,为什么不是一定存在呢?因为一个比特值为 1 有可能会受到其他元素的影响。所以 布隆过滤器是用于检测一个元素是否一定不存在或者有可能存在 。
加入我们有一个布隆过滤器长度为 10,有 3 个哈希函数。这时我们我们将 ”死“插入到布隆过滤器中,经过三个哈希函数得到的哈希值为 3、6、9,则如下:
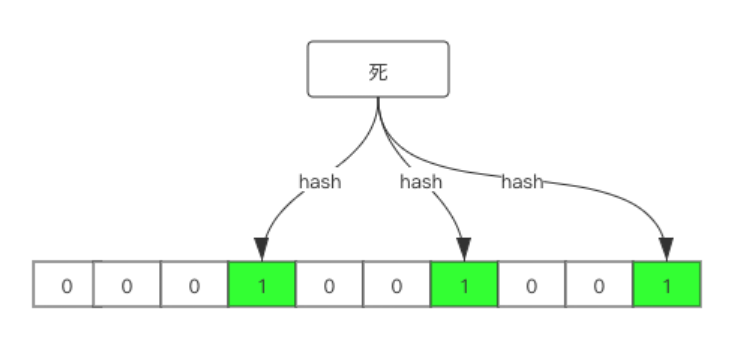
现在我们再存一个值:”磕“,假设得到的哈希值为 1 6 8,如下:
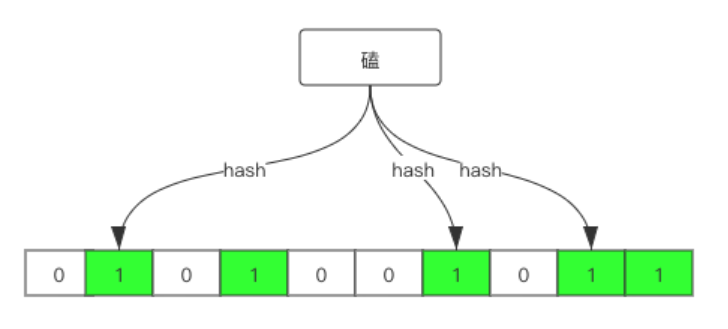
我们再查下 ”Redis“,假设返回的哈希值为 1 5 7,得到的比特值为 1 0 0 ,所以我们可以很确切地说”Redis“这个值一定不存在,如果查询 “Java” 得到的哈希值为 1 6 9,比特值为 1 1 1,那么我们是否可以说一定存在呢?答案是不可以,只能说 “Java” 这个值有可能存在。因为随着数据的增多,越来越多位置的比特值被设置为 1,有可能存在某个值从来没有被存储,但是哈希函数返回的位值都为 1 。
3.优缺点
优点:
- 不需要存储数据,只用比特表示,因此在空间占用率上有巨大的优势
- 检索效率搞,插入和查询的时间复杂度都为 O(K)(K 表示哈希函数的个数)
- 哈希函数之间相互独立,可以在硬件指令层次并行计算,因此效率较高。
缺点:
- 存在不确定的因素,无法判断一个元素是否一定存在,所以不适合要求 100% 准确率的场景
- 只能插入和查询元素,不能删除元素。
4.使用Guava实现布隆过滤器
4.1 导入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>
代码:
public class BuLongFilter {
public static void main(String[] args) {
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")),10000000,0.0001);
bloomFilter.put("死");
bloomFilter.put("课");
bloomFilter.put("redis");
System.out.println(bloomFilter.mightContain("redis"));
System.out.println(bloomFilter.mightContain("Redis"));
}
}
结果:

参考:https://www.cmsblogs.com/article/1391390793981366272