Mysql 之 change buffer(二)
Mysql 之 change buffer
1. 什么是change buffer?
change buffer 是一块缓冲区,存在的就是最新的数据变更。它主要解决的是随机读磁盘IO消耗大的问题。为什么是随机读呢?
如果没有change buffer,当有一条更新语句进来对某条数据进行修改时,需要找到这条数据,优先去从buffer pool 中找,不存在则去磁盘获取。将数据页从磁盘读入buffer pool 涉及随机 IO 访问,这是数据库成本最高的操作之一。所以有了这么一块缓冲区之后,针对某些写入或者修改操作,直接把数据缓存在change buffer 中。当下次查询的时候再从磁盘读出原始数据,将原始数据和change buffer 中 的改动做merge 之后返回。省去的是写操作时可能涉及到的磁盘IO操作。
change buffer 虽然名是buffer,但其实它是可以持久化的,它持久化的地方默认是ibdata1共享空间中。因为为了数据的一致性,change buffer 也是需要写 redo log的。所以redo log 里不仅有针对普通数据页的改动记录,也有change buffer的记录。
说到change buffer 就不得不说buffer pool。顾名思义,缓冲池。我们在做项目工程的时候,遇到了高并发的场景一般都会在db前面加一层redis抗一波,防止大量请求直接把db打挂,那么redis就充当了缓冲作用。buffer pool也类似,server过来的请求先看buffer pool有没有相应的数据,有的话直接返回。反之则需要去磁盘去读。
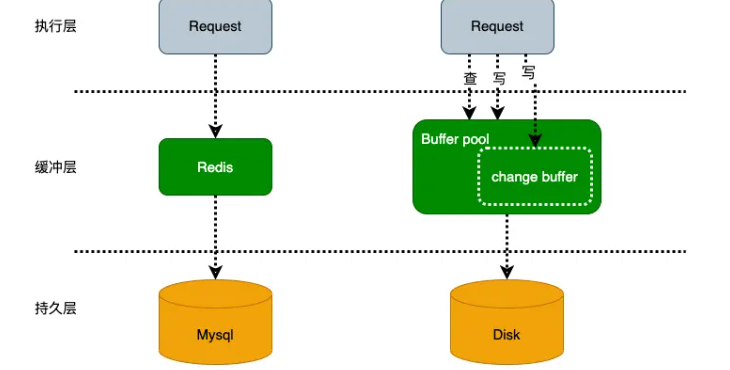
2. change buffer 和 buffer pool关系
如上图所示,change buffer 是 buffer pool 里的一块区域。
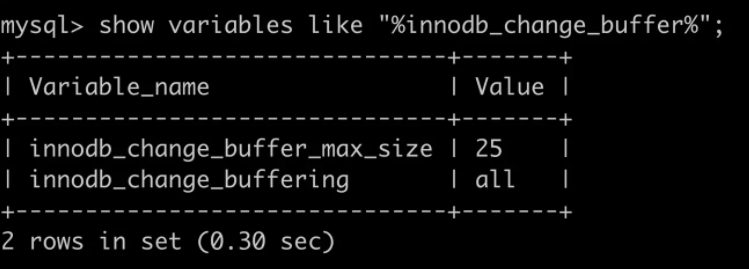
- innodb_change_buffer_max_size 表示change buffer 最大占 buffer pool 的百分比,默认为25%
3. change buffer 几种使用场景
3.1 一条简单的更新语句
- 判断buffer pool是否有该记录
- 如果有该记录则直接进行更新
- 否则将其写入change buffer
- 写 redo log
3.2 一个根据唯一键更新的语句
- 判断buffer pool是否有该记录
- 如果有则直接更新
- 没有则去磁盘查
- 更新buffer pool
- 写 redo log
3.3 一条简单的查询语句
- 判断buffer pool 是否有该记录
- 如果没有则查磁盘
- 判断 change pool 有无该记录
- 有则merge该记录
- 写 redo log
4. 为什么要有change buffer?
4.1 change buffer 解决了什么问题?
将数据页从磁盘读入内存中涉及随机IO访问,这也是数据库里面成本最高的操作之一,而利用写缓存(change buffer)可以减少IO操作,从而提升数据库性能。
4.2 那为啥唯一索引不能利用change buffer呢?
上面流程里面。唯一索引在做insert 或者 update 的时候,需要先判断索引记录的唯一性,所以肯定要先拿到最新的记录。即会将磁盘数据页加载到内存,然后判断。所以既然都加载到内存,那我直接操作内存就好了,就不用搭理change buffer了,不然还得merge有点繁琐。
4.3 change buffer 干掉可以不可以?
change buffer 本身就是一个可选项。
- innodb_change_buffering 参数用来控制对哪些操作启用 change buffer 功能,默认是 all
innodb_change_buffering 参数有以下:
- all : 默认值,开启buffer
- none : 不开启change buffer
- inserts : 只是buffer insert 操作
- deletes: 只是开启delete-marking 操作
- changes: 开启buffer insert 操作和 delete-marking 操作
- purges: 对只是在后台执行得物理删除操作开启buffer功能
不开启的影响就是回到了随机读。当buffer pool 中不存在此数据时,写入操作时会先从磁盘读出数据进buffer pool,再进行下面的操作,每次都是这样,对逻辑及数据准确性没有影响,只是影响性能。