redis五种基本数据结构
redis五种基本数据结构
1. redis为什么快
相比于其他数据库,redis为什么能有这么突出的表现,得益于以下几点:
- redis是基于内存的,所有操作都在内存上完成,内存的访问速度本身就很快
- redis使用了高效的数据结构
- 多路复用io模型
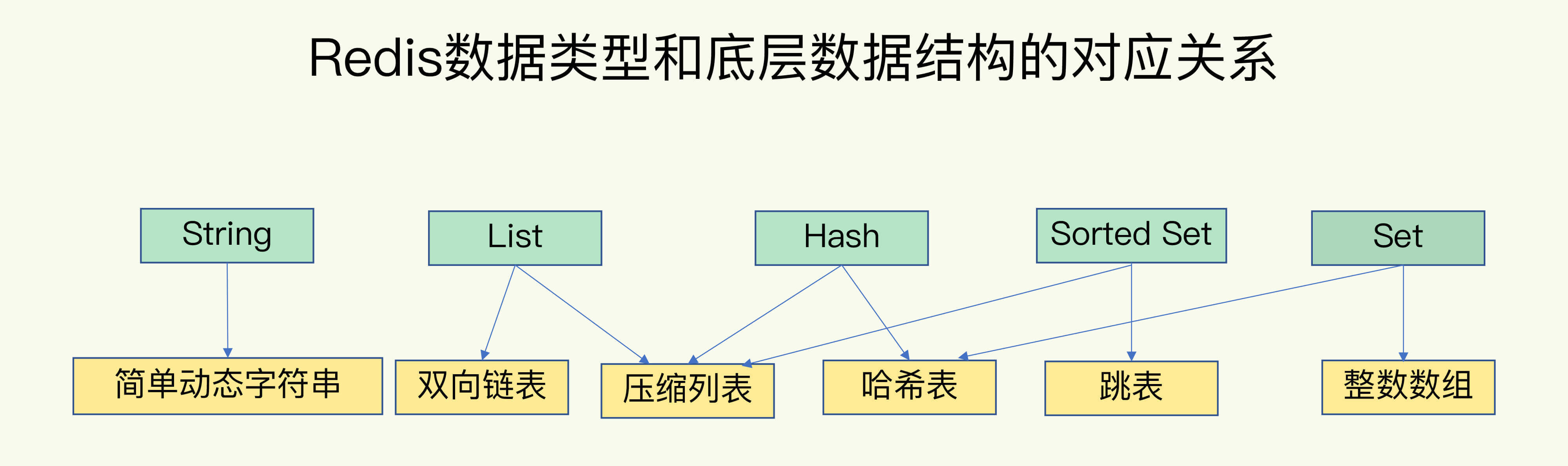
2. redis五种基本数据类型
redis底层有五种基本数据类型: List、Hash、Set 和 Sorted Set,Hash
2.1 String
字符串String是redis最简单的数据结构,底层就是一个字符数组.
相比于普通字符串,redis的字符串是动态字符串,是可以进行修改的,采用预分配冗余空间的方式来减少内存的频繁分配
常用命令
SET:将字符串值 value 关联到 key。如果 key 已经持有其它值, SET 就覆盖旧值【SET key value】;
● GET:获取某个 key 的 value 值【GET key】;
● MGET:一次获得多个 key 的数据【MGET key1 key2 …】,节省网络耗时开销;
● MSET:一次设置多个 key 的数据【MSET key1 value1 key2 value2 …】,节省网络耗时开销;
● EXISTS:判断一个键是否存在,存在返回 1;否则返回 0【EXISTS key】;
● DEL:删除某个 key 或者一些列 key【DEL key1 key2 …】;
● KEYS:返回匹配的 key 列表(KEYS foo* 指查找 foo 开头的 keys)【KEYS *】;
应用场景
- 缓存:常规数据(比如Session、token、序列化后的对象等)的缓存
- 计数器: 用户单位时间的请求数、页面单位时间的访问数
- 分布式锁: 可以使用SETNX key value可以实现一个最简易的分布式锁
动态字符串相比与C语言中字符串的优点
-
可以避免缓冲区溢出:C 语言中的字符串被修改(比如拼接)时,一旦没有分配足够长度的内存空间,就会造成缓冲区溢出。SDS 被修改时,会先根据 len 属性检查空间大小是否满足要求,如果不满足,则先扩展至所需大小再进行修改操作。
-
获取字符串长度的复杂度较低:C 语言中的字符串的长度通常是经过遍历计数来实现的,时间复杂度为 O(n)。SDS 的长度获取直接读取 len 属性即可,时间复杂度为 O(1)。
-
减少内存分配次数:为了避免修改(增加/减少)字符串时,每次都需要重新分配内存(C 语言的字符串是这样的),SDS 实现了空间预分配和惰性空间释放两种优化策略。当 SDS 需要增加字符串时,Redis 会为 SDS 分配好内存,并且根据特定的算法分配多余的内存,这样可以减少连续执行字符串增长操作所需的内存重分配次数。当 SDS 需要减少字符串时,这部分内存不会立即被回收,会被记录下来,等待后续使用(支持手动释放,有对应的 API)。
-
二进制安全:C 语言中的字符串以空字符
\0作为字符串结束的标识,这存在一些问题,像一些二进制文件(比如图片、视频、音频)就可能包括空字符,C 字符串无法正确保存。SDS 使用 len 属性判断字符串是否结束,不存在这个问题
2.2 List
Redis 的列表相当于 Java 语言里面的 LinkedList,注意它是链表而不是数组。这就意味着 list 的插入和删除操作非常快,时间复杂度为 O(1) ,但是索引定位很慢,时间复杂度为 O(n)
常用命令
- LPUSH:将一个或多个值插入到列表头部【lpush key value1 [value2 …]】。
- RPUSH:从尾部加入元素(队列)先进先出【rpush key value1 [value2 …]】。
- LPOP:移除并获取列表中的第一个元素【lpop key】
- RPOP:移除并获取列表中的最后一个元素【rpop key】
- LRANGE:获取列表中指定范围内的元素【lrange key start stop】
- LLEN:获取 List 的长度【llen key】
底层数据结构
当列表元素较少的情况下,会使用压缩列表,它将所有元素都紧挨着一起存储。
当数据比较多的时候才会改成 QuickList。因为普通的链表需要的附加指针空间太大,会浪费空间,还会增加内存的碎片化
应用场景
- 信息流展示: 最新动态、最新动态
- List做消息队列
2.3 Set
Redis 的集合Set 相当于 Java 语言里面的 HashSet,它内部的键值对是无序的、唯一的。它的内部实现相当于一个特殊的HashMap,HashMap 中所有的 value 都是一个 NULL 值。当集合中最后一个元素被移除后,数据结构被自动删除,内存被回收。
常用命令
- SADD:向集合添加一个或多个成员【sadd key value1[value2…]】。
- SISMEMBER:判断集合中是否存在 key 的成员【sismember key value】。
- SMEMBERS:返回集合中的所有成员【smembers key】
- SUNION:返回所有给定集合的并集【sunion key1 [key2…]】
- SINTER:返回所有给定集合的交集【sinter key1 [key2…]】
- SDIFF:返回所有给定集合的差集【sinter key1 [key2…]】
使用场景
- 需要存放的数据不能重复的场景: 网站 UV 统计(数据量巨大的场景还是
HyperLogLog更适合一些)、文章点赞、动态点赞等场景。 - 需要获取多个数据源交集、并集和差集的场景
底层数据结构
set底层数据结构是inset和hashtable两种。intset 编码的对象使用整数集合作为底层实现,把所有元素都保存在一个整数集合里面。
保存元素为整数且元素个数小于一定范围使用 intset 编码,任意条件不满足,则使用 hashtable 编码
2.4 Sorted set
Zset 类似于 Java 的 SortedSet 和 HashMap 的结合体,一方面它是一个 set,保证了内部的唯一性,另一方面它可以给每个 value 赋予一个 score,代表这个 value 的排序权重。
常用命令
- ZADD:向集合中添加一个或多个元素,或者更新已存在的元素【zadd key score1 member1 [score2 member2]】;
- ZRANGE:通过索引区间返回有序集合指定的成员【zrange key start stop [WITHSCORES]】;
- ZRANK:返回集合中指定成员的索引(下标)【zrank key member】;
- ZREM:移除有序集合中一个或多个成员【zrem key member1 [member2 …]】;
- ZREVRANGE:逆向返回有序集中指定区间的成员,通过索引分数从高到低【zrevrange key start stop [WITHSCORES]】;
- ZCARD:相当于 count()【zcard key】;
- ZSCORE:获取指定 value 的 score【zscore key value】;
- ZRANGBYSCORE:根据分值区间遍历 zset【zrangbyscore key start end】
应用场景
- 各种排行榜比如直播间送礼物的排行榜、朋友圈的微信步数排行榜、王者荣耀中的段位排行榜、话题热度排行榜等等。
- 需要存储的数据有优先级或者重要程度的场景 比如优先级任务队列。
底层数据结构
- hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
- 跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表
2.5 Hash
Redis 的字典(Hash)相当于 Java 语言里面的 HashMap,它是无序字典,内部存储了很多键值对。
常用命令
- HSET:将哈希表 key 中的字段 field 的值设为 value【hset key field value】;
- HGET:获取存储在哈希表中指定字段的值【hget key field】;
- HGETALL:获取哈希表中,指定 key 的所有字段和值【hgetall key】;
- HDEL:删除一个或多个哈希表字段【hdel key field1 [field2…]】;
- HMSET:同时将多个 field-value(域-值)设置到哈希表 key【hmset key field value [field1 value1 …]】;
- HLEN:获取 key 中存储的元素个数【hlen key】;
底层数据结构
哈希对象有两种编码方案,当同时满足以下条件时,哈希对象采用ziplist编码,否则采用hashtable编码:
-
哈希对象保存的键值对数量小于512个;
-
哈希对象保存的所有键值对中的键和值,其字符串长度都小于64字节。
其中,ziplist编码采用压缩列表作为底层实现,而hashtable编码采用字典作为底层实现。